

大数据简介
用于分析过去以便进行未来预测的大型数据集称为大数据。它们的主要概念是体积、速度和多样性,因此任何数据都很容易处理。结构化和非结构化数据都会被处理,这不是使用传统的数据处理方法来完成的。它从数据处理流中为任何人提供所需的信息。它被用于研究、分析、医疗领域、教育以及处理海量数据的地方。它是从社交媒体、机器数据和事务数据演变而来的。

什么是大数据
下面的文章为大数据的介绍提供了一个提纲。传统的数据处理无法处理庞大而复杂的数据。因此,我们使用大数据来分析、提取信息,更好地理解数据。我们考虑体积,速度,多样性,准确性和价值的大数据。大数据的一个例子是通过社交媒体生成的人的数据。大数据有助于分析数据中的模式,以便轻松理解人们和企业的行为。这有助于高效处理,从而提高客户满意度。大数据中涉及的数据可以是结构化的或非结构化的,也可以是自然的或经过处理的,或者与时间有关。
大数据的主要组成部分
以下是大数据的主要组成部分:
Hadoop、数据科学、统计和;其他
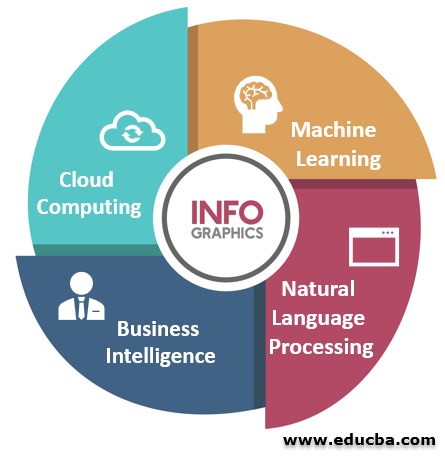
1。机器学习
这是一门让计算机自己学习的科学。在机器学习中,计算机需要使用算法和统计模型来执行特定的任务,而不需要任何明确的指令。机器学习应用程序提供基于过去经验的结果。例如,现在有一些移动应用程序可以为你提供财务、账单的摘要,提醒你账单的支付情况,还可以为你提供一些储蓄计划的建议。这些功能是通过阅读电子邮件和短信来完成的。
2。自然语言处理(NLP)
它是计算机理解人类语言的能力。现在人们能想到的最明显的例子是谷歌主页和亚马逊Alexa。两者都使用NLP和其他技术为我们提供虚拟助手体验。NLP就在我们身边,我们甚至都没有意识到。在写邮件时,如果出现任何错误,它会自动更正自己,现在它会自动给出完成邮件的建议,并在我们试图发送一封没有电子邮件文本中引用的附件的电子邮件时自动恐吓我们,这是在后端运行的自然语言处理应用程序的一部分。
3。商业智能
商业智能(BI)是一种技术驱动的方法或流程,通过分析数据并以最终用户(通常是高层管理人员)如经理和企业领导人可以从中获得一些可操作的见解并对其做出明智的商业决策的方式来获取见解。
4。云计算
如果我们按名称来命名,它应该是在云上进行计算的;嗯,这是真的,这里我们不是在谈论真正的云,这里的云是互联网的参考。因此,我们可以将云计算定义为提供计算服务——服务器、存储、数据库、网络、软件、分析、智能,以及互联网(“云”),以提供更快的创新、灵活的资源和规模经济。
大数据的特点
以下是大数据的特点:
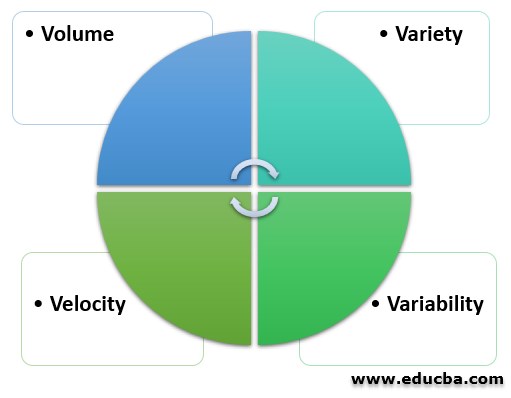
- 体积:为了确定数据的价值,需要考虑数据的大小,这一点至关重要。此外,为了确定特定类型的数据是否属于“大数据导论”类别,它取决于数据量</李>
- 多样性:多样性是指根据数据的性质(结构化和非结构化)不同的数据类型。之前,大多数应用程序考虑的唯一数据源是行和列的形式,它们通常以电子表格和数据库的形式出现。但如今,数据以我们能想象的任何形式出现,比如电子邮件、照片、视频、音频等等</李>
- 速度:速度,顾名思义,是数据生成的速度。从一个来源来看,数据生成的速度和处理的速度决定了数据的潜力</李>
- 可变性:数据可能是可变的,这意味着它可能不一致,而不是在流程中,从而干扰或成为以有效方式处理和管理数据的障碍</李>
大数据的应用
大数据分析的使用方式如下:
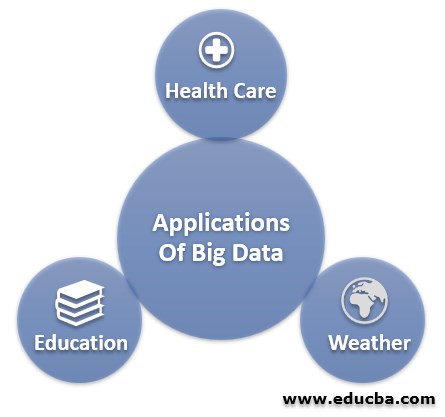
- 医疗:我们现在有可穿戴设备和传感器,可以实时更新患者的健康状况</李>
- 教育:通过大数据分析进行适当分析,可以跟踪和改进学生的进步</李>
- 天气:部署在全球各地的天气传感器和卫星收集大量数据,并使用这些数据监测天气和环境状况,还预测或预测未来几天的天气状况</李>
大数据的优缺点
以下是优点和缺点:
</t车身>
| 优势 | 缺点 |
| 更好的决策 | 数据质量:数据质量需要良好,并安排好进行大数据分析 |
| 提高生产力 | 硬件需求:需要存储数据的存储空间,以及在分析系统之间传输数据所需的网络带宽,这些都是购买和维护大数据环境的昂贵成本 |
| 降低成本 | 网络安全风险:存储敏感和大量数据会使公司成为网络攻击者更具吸引力的目标,网络攻击者可能会将数据用于勒索或其他不法目的 |
| 改善客户服务 | 在与传统系统集成方面遇到了困难:许多长期经营的老企业在不同的体系结构和环境中,将数据存储在不同的应用程序和系统中。这在整合过时的数据源和移动数据方面产生了问题,进一步增加了处理大数据的时间和费用 |
理解V
以下是提到的理解:
Hadoop、数据科学、统计和;其他
1。音量
处理和处理大量数据是一个常见问题。它利用Hadoop、Apache Spark和HDFS等其他技术轻松地执行任务。
2。速度
组织高速收集数据以处理即时结果。它可以应对这种情况,提供无缝的处理和结果。股票交易所和天气预报就是一些实时的例子。
3。多样性
- 结构化:从关系数据库派生的预设格式的数据集。例如,一个员工的工资表上有一个预定义的模式</李>
- 非结构化:这些是没有正确格式或对齐的随机数据。因此,它们需要更多的处理时间。例如谷歌搜索、社交媒体民意调查、视频流</李>
- 半结构化:它是结构化和非结构化数据的组合。它们有适当的结构,但缺乏所需的定义</李>
如何使工作变得更容易
在此之前,对现有数据进行了线性和逐行分析。后来随着计算机的引入,Excel电子表格使生活变得简单。用户需要将不同的记录制成表格,并进行必要的研究,以得出有意义的报告。它在许多方面改变了游戏规则。可以处理和分析高达TB的大量数据集。应用了复杂的查询和算法。生成的报告具有更好的结果,几乎没有失败。所有这些都需要几分钟到几小时的时间,这取决于数据的大小。
顶级公司
它被广泛应用于制造业、医疗保健、能源、保险、体育等领域。一些顶级公司如下所示:
- IBM
- 微软
- 亚马逊
- 惠普企业
- Teradata
组成部分
下面列出了各种第三方工具,可用于对来源提供的数据进行分析。它们可以独立运行,也可以与其他组件协作。
- Hadoop
- HDFS
- Sqoop
- 地图缩小
- 阿帕奇星火/风暴
- 谷歌大查询
- 亚马逊运动
用例
- 管理层可以做出更好的决策</李>
- 识别客户需求的趋势并保持相关性</李>
- 低风险结果</李>
- 决策验证</李>
- 确定了目标受众</李>
工作
借助Hadoop等第三方工具,Spark可以将大型数据集加载到外部存储。数据是基于人工编写的查询进行处理的。商业智能团队利用这些报告来理解预测模式并纠正以前的错误。此外,数据可以可视化,以做出有用的决策。
优势
- 可以完全理解业务目标</李>
- 学习数字背后的含义</李>
- 分析以前失败的根本原因</李>
- 使用易于理解的语言洞察未来结果</李>
- 有助于做出完美的决策</李>
先决条件
使用它的工具没有先决条件。掌握Java或Python等编程语言的基本知识会有所帮助。了解数据库如何工作和原始查询就足够了。还有其他高级语言,如Spark、Pig等,易于学习和使用。用户应该在技术上合理地使用这些工具来获得所需的输出。
为什么要用它
它用于改进应用程序和服务,以提供更好的结果。可以衍生出各种经济高效的解决方案。随着环境的快速变化,了解客户需求至关重要。
范围
数据永远不会过时,而且随着尖端技术的发展,数据正以指数级增长。这一领域对专业人士有着巨大的需求。它正在演变,具有巨大的增长潜力。分析人员通过正确使用这些技术成为公司的决策者。
需要
如今,数据以不同的形式出现。由于实施成本和缺乏专业人员,许多分析解决方案在过去不可能实现。这样,我们就能够在一个时间间隔内对机器数据执行复杂的算法。它们有许多实时用例,比如欺诈检测、全球平台上的目标受众、网络广告等。
目标受众
利用其组件实现以下目标的组织:
- 预测客户的未来趋势和行为模式</李>
- 以有用的方式分析、理解和展示数据</李>
- 跟上竞争对手并在市场中保持相关性</李>
- 做出强有力的决定</李>
总结——什么是大数据
随着需求和竞争的增长,专业人士保持更新至关重要。通过有效地利用个人和组织可以从多个方面获益。分析师们对这个行业有了更好的了解,并将其传达给了工人们。决策可以根据报告做出,而不是依靠猜测和直觉。











