

大数据架构简介
在管理海量数据和对海量数据进行复杂操作时,需要使用大数据工具和技术。当我们说使用大数据工具和技术时,我们实际上是指我们要求利用大数据生态系统及其领域中的各种软件和程序。没有针对每个用例提供的通用解决方案,因此必须根据特定公司的业务需求以有效的方式精心设计和制造。因此,需要利用不同的大数据架构,因为各种技术的组合将导致最终的用例得以实现。通过建立固定的体系结构,可以确保为所请求的用例提供可行的解决方案。
什么是大数据架构
- 该体系结构的设计方式是,它处理摄取过程、数据处理和数据分析,这对于处理传统数据库管理系统来说太大或太复杂</李>
- 不同的组织对其组织有不同的阈值,一些组织的阈值为几百GB,而对于其他组织,即使是一些TB也不足以作为阈值</李>
- 由于这一事件的发生,如果你看一下商品系统和商品存储,存储的价值和成本已经显著降低。数据种类繁多,需要以不同的方式满足需求</李>
- 其中一些是在特定时间出现的批处理相关数据,因此需要以类似的方式安排作业,而另一些属于流媒体类,其中必须构建实时流媒体管道以满足所有要求。所有这些挑战都由大数据架构解决</李>
大数据架构解读
Hadoop、数据科学、统计和;其他
大数据系统涉及多种工作负载类型,大致分为以下几类:
- 在基于大数据的数据源处于静止状态的情况下,需要进行批处理</李>
- 动态大数据处理用于实时处理</李>
- 探索交互式大数据工具和技术</李>
- 机器学习和预测分析</李>
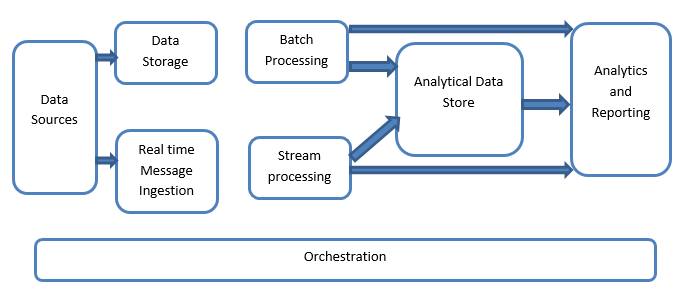
1。数据来源
数据源包括所有黄金来源,数据提取管道就是从这些黄金来源建立起来的,因此这可以说是大数据管道的起点。
示例包括:
(i) 应用程序的数据存储,比如关系数据库
(ii)由多个应用程序生成的文件,主要是静态文件系统的一部分,例如基于web的服务器文件生成日志。
(iii)物联网设备和其他实时数据源。
2。数据存储
这包括为批量构建操作管理的数据,存储在文件存储区中,这些文件存储区本质上是分布式的,并且能够存储大量不同格式的大文件。它被称为数据湖。这通常是我们的Hadoop存储(如HDFS、Microsoft Azure、AWS、GCP存储)与blob容器一起提供的部分。
3。批处理
所有数据都被划分为不同的类别或区块,利用长期运行的作业进行过滤和聚合,并为分析处理状态的数据做好准备。这些作业通常使用源,对其进行处理,并将处理后的文件输出到新文件。批处理以各种方式完成,方法包括使用Hive作业或基于U-SQL的作业,或使用Sqoop或Pig以及自定义map reducer作业,这些作业通常用Java或Scala或任何其他语言(如Python)编写。
4。基于实时的消息接收
与批处理不同,这包括所有实时流系统,这些系统以固定模式按顺序生成数据。这通常是一个简单的数据集市或存储区,负责所有传入的消息,这些消息被放入必要用于数据处理的文件夹中。然而,大多数解决方案都需要基于消息的摄取存储,它充当消息缓冲区,还支持基于规模的处理,与其他消息队列语义一起提供相对可靠的传递。这些选项包括ApacheKafka、ApacheFlume、Azure的事件中心等。
5。流处理
实时消息摄取和流处理之间有细微的区别。前者考虑了最初收集的摄取数据,然后将其用作一种发布-订阅工具。另一方面,流处理用于处理windows或流中发生的所有流数据,然后将数据写入输出接收器。这包括Apache Spark、Apache Flink、Storm等。
6。基于分析的数据存储
这是用于分析目的的数据存储,因此,可以使用与BI解决方案相对应的分析工具来查询和分析已处理的数据。数据还可以借助NoSQL数据仓库技术(如HBase)或任何交互式使用hive database来呈现,后者可以在数据存储中提供元数据抽象。工具包括Hive、Spark SQL、Hbase等。
7。报告和分析
必须根据处理后的数据生成洞察,这是由报告和分析工具有效完成的,这些工具利用其嵌入式技术和解决方案生成对业务有用的图表、分析和洞察。工具包括Cognos、Hyperion等。
8。编排
基于大数据的解决方案包括与数据相关的操作,这些操作本质上是重复的,并且也封装在工作流中,这些工作流可以转换源数据,还可以跨源和汇移动数据,并在存储中加载,并推送到分析单元中。示例包括Sqoop、oozie、数据工厂等。
结论
在这篇文章中,我们了解了大数据体系结构,这是在公司或组织中实施这些技术所必需的。希望你喜欢我们的文章。
推荐文章
这是大数据架构的指南。这里我们讨论了什么是大数据?我们还展示了大数据的体系结构以及方框图。您也可以浏览我们建议的其他文章以了解更多信息——











