
大数据和Hadoop简介
数据每天都呈指数级增长,随着数据的增长,需要利用这些数据。和以前一样,我们过去用软驱来存储数据,数据传输也很慢,但现在,这些都不够了,云存储被使用,因为我们有TB的数据。当今世界,社交媒体对数据增长的贡献最大。它包括人们的行为、心态和其他几个方面。据说每分钟有300小时的视频上传到YouTube上,超过2000万张照片上传到Facebook和其他许多网站上。此外,上传的数据没有适当的结构,这是处理这些数据的最大挑战。
随着海量数据的高速生成,传统的RDBMS系统无法处理如此快速的增长。此外,它们也无法处理非结构化数据。处理如此大量快速增长的异构数据并以高速处理这些数据变得非常困难。因此,需要这样一个能够高效处理大型数据集的系统。因此,为了解决这个问题,Hadoop应运而生。HDFS是Hadoop的组件,通过使用分布式存储解决了大型数据集的存储问题,而YARN则是解决处理问题的组件,大大缩短了处理时间。
Hadoop、数据科学、统计和;其他
Hadoop是一个开源软件框架,用于使用分布式大型商用硬件集群存储和处理大数据集。它由Doug Cutting和Michael J.Cavarella开发,并在Apache下获得许可。它是用Java编写的,是基于Google在MapReduce系统上写的论文开发的,它应用了函数式编程的概念。它可靠、经济、灵活、可扩展。
Hadoop的核心组件
核心组件如下所示
HDFS
HDFS或Hadoop分布式文件系统有Namenode和data node。Namenode是运行主守护进程的主节点,它管理数据节点并跟踪所有操作。数据节点是实际存储数据的从属节点。
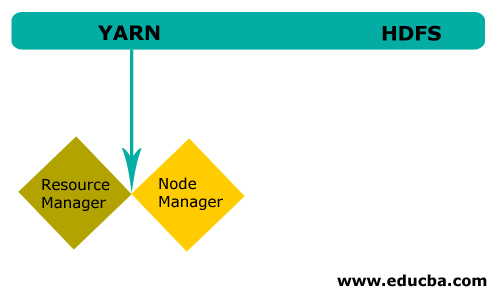
纱线
纱线由两个主要成分组成:
1。ResourceManager:它在主节点上运行,管理所有资源,并调度所有应用程序。它有调度器&;应用程序管理器。
2。NodeManager:它在每个从属节点上运行,负责管理容器和监控资源利用率。
这类热门课程
Hadoop的几个组件
有几个组件,如猪、蜂巢、sqoop、水槽、mahout、oozie、zookeeper、HBase等。
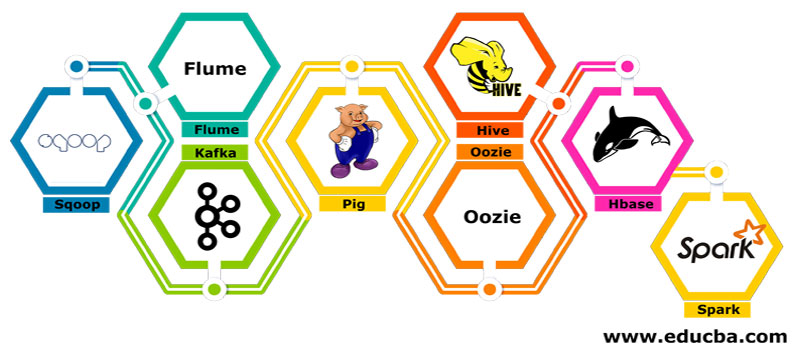
- Sqoop–它用于将数据从RDBMS导入和导出到Hadoop,反之亦然</李>
- Flume–它用于将实时数据拉入Hadoop</李>
- 卡夫卡–这是一个用于路由实时数据的消息传递系统</李>
- Pig–它被用作数据处理的脚本语言</李>
- Hive–它是一个基于HDFS的数据仓库框架,让熟悉SQL的用户可以执行查询以获取数据。这些查询称为HiveQL</李>
- Oozie–它用于安排作业的工作流在指定的事件或时间上运行</李>
- Hbase–它是作为Apache Hadoop的一部分提供的无SQL数据库</李>
- Spark–它用于执行内存处理,比Hadoop map reduce快得多</李>
Hadoop提供者
有很多公司提供Hadoop发行版。
以下是几个最好的供应商:
- 克劳德拉
- 霍顿工厂
- MapR
学习Hadoop有几个先决条件。有Java和脚本语言经验者优先。尽管它已经有了自己的高级编程语言,比如pig和hive,它们可以生成后端代码以供进一步处理,但仍然可以用Ruby、Python、Perl甚至C编程等任何编程语言创建自己的map reduce程序。
Bigdata和Hadoop在当今市场上的需求量很大。在接下来的几天里,这将增加更多。很多组织已经开始使用Hadoop,而那些没有使用Hadoop的组织将很快开始使用Hadoop。目前有一份报告称,大公司已经开始投资大数据分析。大数据营销预测总是处于上升趋势,而且根本不是一种短命状态。除此之外,与其他技术相比,Hadoop和大数据领域的工作总是提供高薪。
顶级大数据和Hadoop公司
以下是雇佣人数最多的几家顶级公司:
- 领英
- 雅虎
- 亚马逊
- 苏格兰皇家银行
- 英国航空公司
- Expedia
- 沃尔玛
很多公司都在使用大数据应用程序。这些是:
诺基亚
它使用Cloudera和Hadoop组件,比如应用程序的HDFS、HBase、Sqoop和Scribe。它有效地使用用户数据来理解和改善用户体验。它使用数据处理和复杂分析来构建具有预测交通和分层高程模型的地图。
SAS
它与Hadoop合作,通过提供一个提供视觉和交互体验的环境,帮助数据科学家获得更好的洞察力,从而帮助探索新趋势。分析程序从数据中提取有意义的见解,内存技术有助于更快地访问数据。
还有很多其他公司使用大数据平台进行各种分析。这些是航空业黑匣子的飞行数据分析,股票市场的差异分析,等等。
Hadoop的优势
以下是Hadoop的一些优点:
- 可扩展性–与传统的RDBMS不同,它是一个高度可扩展的平台,因为它可以在并行运行的商品硬件上以分布式集群存储大型数据集</李>
- 经济高效——对于RDBMS来说,存储数据的成本太高,而Hadoop已经减轻了这一成本</李>
- 快速灵活——它通过分布式文件系统提供快速访问数据的功能。它还提供从半结构化和非结构化数据中获取业务见解的功能</李>
- 容错——每当任何数据被发送到一个节点时,相同的数据都会被复制到其他节点,在第一个节点出现故障时可以访问这些节点</李>
总结——什么是大数据和Hadoop
数据在不断增长,因此总是需要大数据和Hadoop来利用这些数据。因此,具备Hadoop技能的专业人士在未来几天内总能找到大量机会,并且可以成为推动企业发展和职业生涯的重要资产。
推荐文章
这是关于什么是大数据和Hadoop的指南。这里我们讨论了大数据和Hadoop的基本概念和组件。您还可以阅读以下文章了解更多信息——











