
什么是kafka?
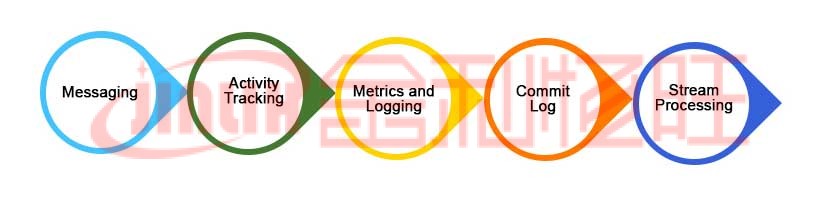
LinkedIn开发的用于处理实时数据的开源软件平台称为Kafka。它发布和订阅记录流,也用于容错存储。这些应用程序旨在处理时间和使用记录。不同服务器的日志分区在 Kafka 中进行复制。它存储、读取和分析开发人员和用户贡献编码更新的流数据。它用于消息传递、网站活动跟踪、日志聚合和提交日志。它可以用作数据库,但它不具备数据模型或索引。

Apache Kafka 是一种分布式数据存储,经过优化以实时提取和处理流数据。流数据是指由数千个数据源持续生成的数据,通常可同时发送数据记录。流平台需要处理这些持续流入的数据,按照顺序逐步处理。
Kafka 为其用户提供三项主要功能:
发布和订阅记录流
按照记录的生成顺序高效地存储记录流
实时处理记录流
Kafka 主要用于构建适应数据流的实时流数据管道和应用程序。它结合了消息收发、存储和流处理功能,能够存储历史和实时数据。
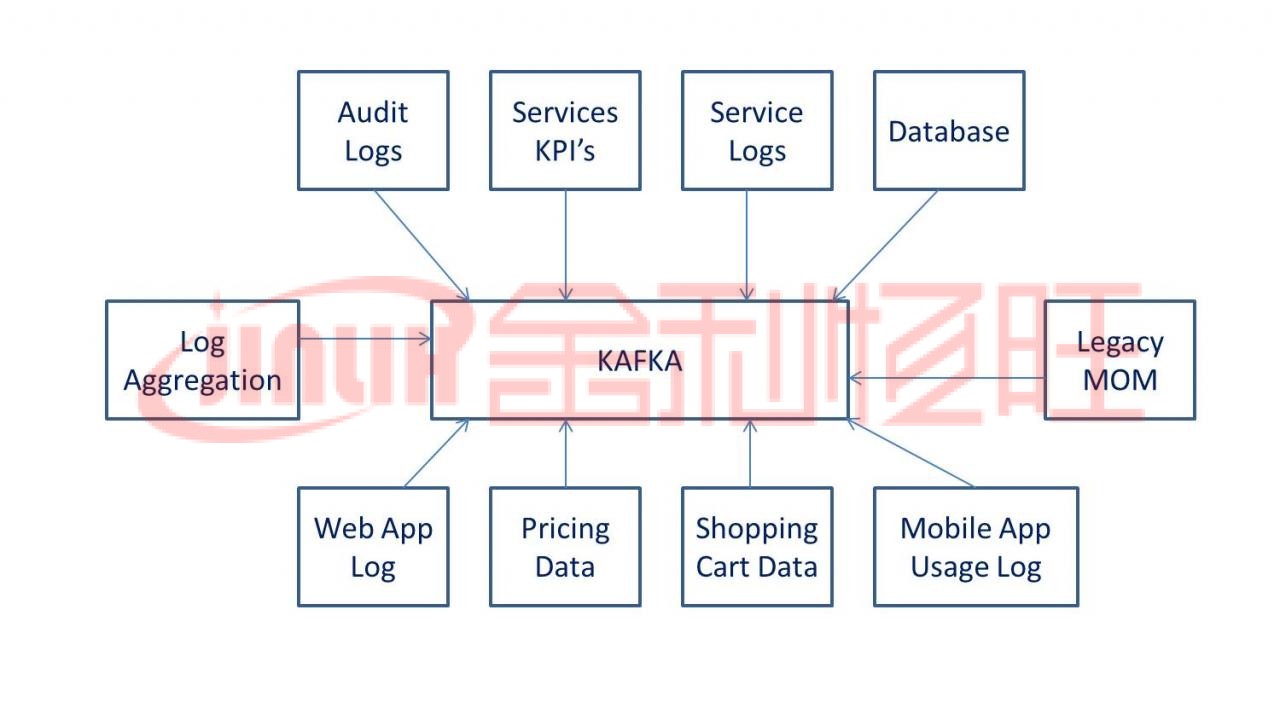
为什么使用 Kafka?
Kafka 用于构建实时流数据管道和实时流应用程序。数据管道在不同系统之间可靠处理和移动数据,而流应用程序是消耗数据流的应用程序。例如,如果您要创建获取用户活动数据的数据管道以实时追踪人们如何使用您的网站,Kafka 将可在使支持数据管道的应用程序完成读取操作的同时,用于提取和存储流数据。Kafka 还经常用作消息代理解决方案,充当平台来处理和调解两个应用程序之间的通信。
了解kafka
它的增长呈指数级增长。让我们看看一些事实和统计数据,以更好地强调我们的想法。它享有全球超过三分之一的财富 500 强企业的首选。这种分布由旅游公司、电信巨头、银行和其他几家公司共享。LinkedIn、Microsoft 和 Netflix 每天使用 Kafka 处理四个逗号的消息(几乎等于 1,000,000,000,000)。
它用于实时数据流、收集大数据或进行实时分析(或两者兼而有之)。它与内存中的微服务一起使用以提供持久性,并可用于将事件提供给 CEP(复杂事件流系统)和 IoT/IFTTT 式自动化系统。
Kafka 的工作原理
Kafka 结合了两种消息收发模型、列队和发布-订阅,以向客户提供其各自的主要优势。通过列队可以跨多个使用器实例分发数据处理,因此具有很高的可扩展性。但是,传统队列不支持多订阅者。发布-订阅方法支持多订阅者,但是由于每条消息传送给每个订阅者,因此无法用于跨多个工作进程发布工作。Kafka uses 使用分区日志模型将这两种解决方案融合在一起。日志是一种有序的记录,这些日志分成区段或分区,分别对应不同的订阅者。这意味着,同一个主题可有多个订阅者,分别有各自的分区以获得更高的可扩展性。最后,Kafka 的模型带来可重放性,允许多个相互独立的应用程序从数据流执行读取以便按自己的速率独立地工作。
列队

发布-订阅

kafka为什么那么快呢?
由简单驱动将是定义性能的正确方法。从它的设置和使用中很容易弄清楚 Kafka 是如何如此轻松地工作的。这种提高的行为性能致力于其稳定性,提供可靠的持久性,以及灵活的内置发布或订阅或队列维护功能。如果您需要处理 N 数量的客户端组,如果您必须在市场上展示强大的复制,以向您的客户提供一致的方法(即 Kafka 主题分区),那么这一点至关重要。Kafka 使其与竞争对手区分开来的关键行为是它与具有数据流的系统的兼容性——它的过程使这些系统能够聚合、转换和加载其他存储以方便工作。“如果kafka很慢,上述所有事实都是不可能的”。
随着 Kafka 工作的进一步简化,我们必须进入“操作系统级别”。
让我们看看 Kafka 在操作系统级别是如何工作的:
- 它依靠操作系统内核来更快地移动数据,并根据零拷贝原理工作。
- 它允许将数据记录批处理成块,这些块可以从文件系统(又名 Kafka 主题日志)中看到给消费者。
- 批处理数据的功能提供了有效的数据压缩和 I/O 延迟减少。
- 它具有通过分片水平扩展的能力。它可以将标题日志分成数百到数千个分区。这使它能够轻松处理大量工作量。
Kafka 应用概述
IT 行业的热门领域之一是大数据。该公司处理大量客户数据并获得有用的见解,以帮助他们的业务并为客户提供更好的服务。挑战之一是处理这些大量数据并将其从一端传输到另一端以进行分析或处理;这就是 Kafka(一种可靠的消息传递系统)发挥作用的地方,它有助于实时收集和传输大量数据。Kafka 专为分布式高吞吐量系统而设计,非常适合大规模消息处理应用程序。Kafka 支持当今许多最好的商业和工业应用程序。需要具有强大技能和实践知识的卡夫卡专业人员。
本文将了解 Kafka、它的特性、用例,并了解一些使用它的著名应用程序。
顶级 Kafka 应用程序
本文的这一部分将看到一些流行和广泛实现的用例,并看到一些 Kafka 的实际实现。
现实生活中的应用
1. Twitter:流处理活动
Twitter 是一个社交网络平台,它使用 Storm-Kafka(一种开源流处理工具)作为其流处理基础设施的一部分。反过来,输入数据(推文)被用于聚合、转换和丰富,以供进一步使用或后续处理活动。
2. LinkedIn :流处理和度量
LinkedIn 使用 Kafka 进行流数据和运营指标活动。LinkedIn 使用 Kafka 的附加功能(例如 Newsfeed)来消费消息并对接收到的数据进行分析。
3. Netflix :实时监控和流处理
Netflix 有自己的摄取框架,可将输入数据转储到 AWS S3 中,并使用 Hadoop 运行视频流分析、UI 活动、事件以增强用户体验,并使用 Kafka 通过 API 进行实时数据摄取。
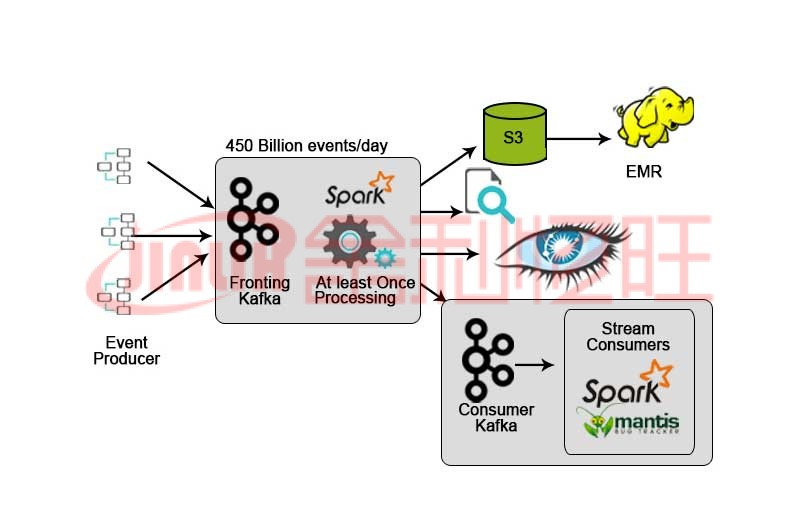
4. Hotstar :流处理
Hotstar 推出了自己的数据管理平台——Bifrost,其中 Kafka 用于数据流、监控和目标跟踪。由于其可扩展性、可用性和低延迟能力,Kafka 非常适合处理 Hotstar 平台每天或在任何特殊场合(任何音乐会直播或任何现场体育比赛等)生成的数据的数据显着增加。
大多数时候,Apache Kafka 被用作开发流数据架构的构建块。这种架构用于收集产品/服务器日志、分析点击流以及从机器生成的数据中获取信息等应用程序中。
但与 Kafka 一起,我们需要使用额外的资源或工具将获得的数据流转换为有意义的数据,以帮助获得可用于数据驱动决策的洞察力。例如,我们可能需要实时从物联网设备获得的原始数据 或从社交媒体平台获得的数据中生成洞察力,并进行一些分析或处理,并将其展示给业务部门,以做出更好的决策或帮助他们改进他们服务的表现。
对于这些类型的用例,我们希望将输入数据/原始数据流式传输到数据湖中,以存储我们的数据并确保数据质量而不影响性能。
另一种情况,我们可能直接从 Kafka 读取数据,是当我们需要极低的端到端延迟时,例如将数据提供给实时应用程序。
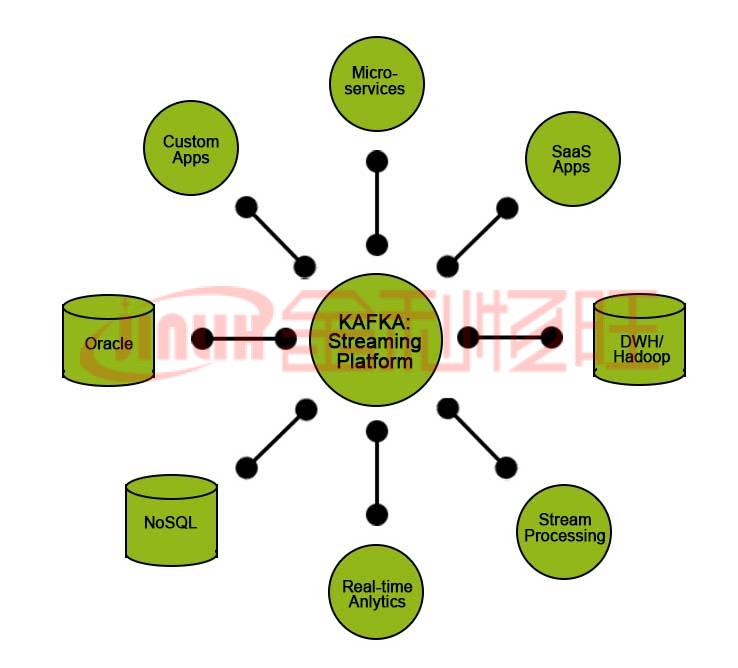
Kafka 为其用户提供了某些功能:
- 发布和订阅数据。
- 按有效生成的顺序存储数据。
- 实时/即时处理数据。
卡夫卡,大多数时候,用于:
- 实现在系统中的两个实体之间可靠地获取数据的动态流数据管道。
- 实现转换或操纵或处理数据流的动态流应用程序。
用例
以下是 Kafka 应用程序的一些广泛实施的用例:
1. 消息传递
Kafka 比 ActiveMQ、RabbitMQ 等其他传统消息系统工作得更好。相比之下,Kafka 提供了更好的吞吐量、内置的分区设施、复制和容错能力,使其成为更适合大规模处理应用程序的消息系统。
2. 网站活动追踪
可以通过 Kafka 或 Kafka 跟踪和馈送用户活动(页面查看、搜索或任何操作)以进行实时监控或分析,以将这些类型的数据存储到Hadoop 或数据仓库中以供以后处理或操作。活动跟踪会生成大量数据,需要将这些数据传输到所需位置而不会丢失数据。
3. 日志聚合
日志聚合是将来自应用程序的不同服务器的物理日志文件收集/合并到单个存储库(文件服务器或 HDFS)中进行处理的过程。与 Flume 相比,Kafka 提供了良好的性能和更低的端到端延迟。

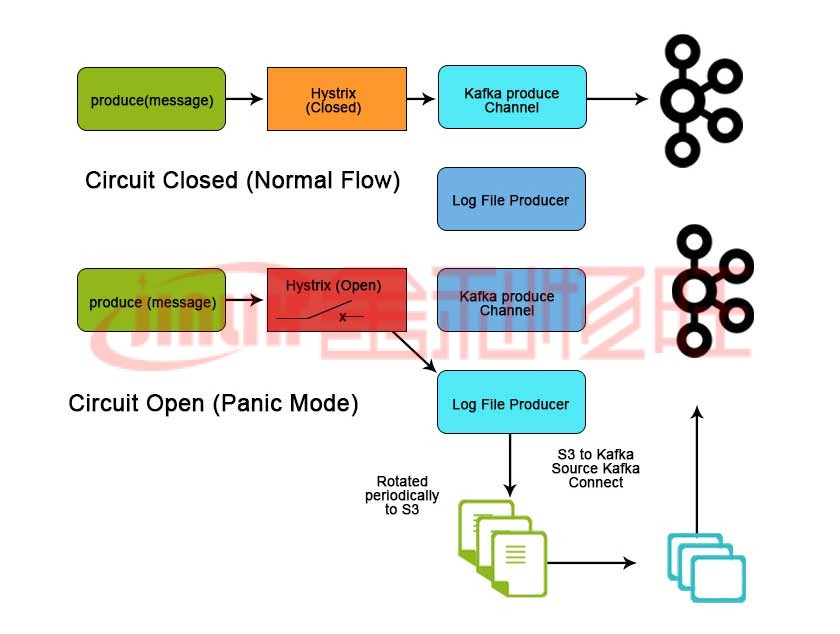
结论
Kafka 在大数据空间中被大量使用,以非常快速地摄取和移动大量数据,因为它的性能特征和特性有助于实现可扩展性、可靠性和可持续性。在本文中,我们讨论了 Apache Kafka 的特性、用例和应用程序,使其成为更好的流数据工具。
你可以用kafka做什么?
如果您的公司经常处理大量数据,那么您需要 Kafka。有很多公司在使用它。
- LinkedIn 使用它来跟踪数据和运营指标。
- Twitter 提供流处理基础设施。
从优步到 Spotify,从高盛到思科,有很多公司。
优点
以下是提到的优点:
- 高吞吐量:它可以在高速生成时轻松处理大量数据,这是对 Kafka 有利的一个特殊优势。该应用程序缺乏巨大的硬件来支持每秒数千条消息的频率的消息吞吐量。
- 低延迟:处理这种大量消息生成的低延迟。
- 容错:这个功能很方便;它具有受集群中内置节点限制的固有能力。
- 耐用:它的操作非常耐用,这也是许多跨国公司更喜欢使用 Kafka 的原因。谈到操作的持久性,从长远来看,消息不会丢失。
所需技能
成为 Kafka 专业人士没有特殊要求。
但我们强调了一些流和专业人士:
- 愿意在大数据流中从事职业并希望加速其职业生涯的开发人员。
- 就队列和消息系统而言,测试专业人员在 Kafka 中有很好的范围。
- 架构师——因为一切都需要一些框架,而且这个框架可以不时更新。大数据架构师会发现 Kafka 是一项很好的职业投资。
- 如果有上述专业人员可以更好地管理资源,则需要项目经理。因此,Kafka领域的管理专业人员也可以获得更高的职位。
为什么使用kafka?
为了根据业务需要跟踪和处理数据,它在全球范围内都是首选。它提供了通过实时分析实时流式传输数据的可能性。它快速、可扩展、耐用,并且设计为容错。Web 上有多个用例,您可以从中了解为什么 JMS、RabbitMQ 和 AMQP 甚至不被认为可以使用,因为需要操作大量和响应能力。
它具有高吞吐量、具有复制特性的可靠设置,使其成为在物联网传感器上工作的首选。
兼容性是使用它并使其在全球范围内接受的另一个原因。它可以轻松配置为与下面列出的应用程序一起使用。这种组合对于许多公司发展业务和生存至关重要(因为它可以节省时间和金钱)。
- 水槽
- 火花流
- HBase
- Spark 用于数据的实时摄取、处理和分析。
- 它用于提供 Hadoop BigData。
范围
它在全球范围内都做得很好。好吧,我们不是说这个而是统计数据。
kafka专业人士的薪资统计 - PayScale
- 软件工程师——109,825 美元
- 数据工程师——109,580 美元
- 开发人员——81,182 美元
- 高级数据工程师——127 美元,836 美元

结论
目前,kafka已经成为实时数据分析的事实标准,精度最高,以微秒为单位。我们在数据和细节方面提出了我们的见解,以支持 Kafka 技术。几家大公司每天都在利用数据;为此,他们需要专业人员来利用这些庞大的数据集。使用 Kafka,可以确保在大数据分析领域引领他们的职业生涯。









